Adding a Reddit feed to your Discord with Python
I’m a moderator of many Discords, and I run a lot of bots and scripts to help manage and improve communities. It’s pretty common for larger subreddits to have a Discord server these days, and for that reason, today we’re going to be looking at a useful feature for both users and moderators alike: adding a Reddit feed to your Discord server.
What we’ll be doing
We’re going to create a separate channel in our Discord server, and receive updates about any new posts within a given subreddit. We’ll be using /r/discordapp for this post. We’ll create a Python script to do the work for us, and this script will need to live somewhere (such as a Digital Ocean VPS - click for free credit).
Create a Discord channel and webhook
For this example, we will first create a new channel called #reddit-feed, with read-only permissions for everyone:
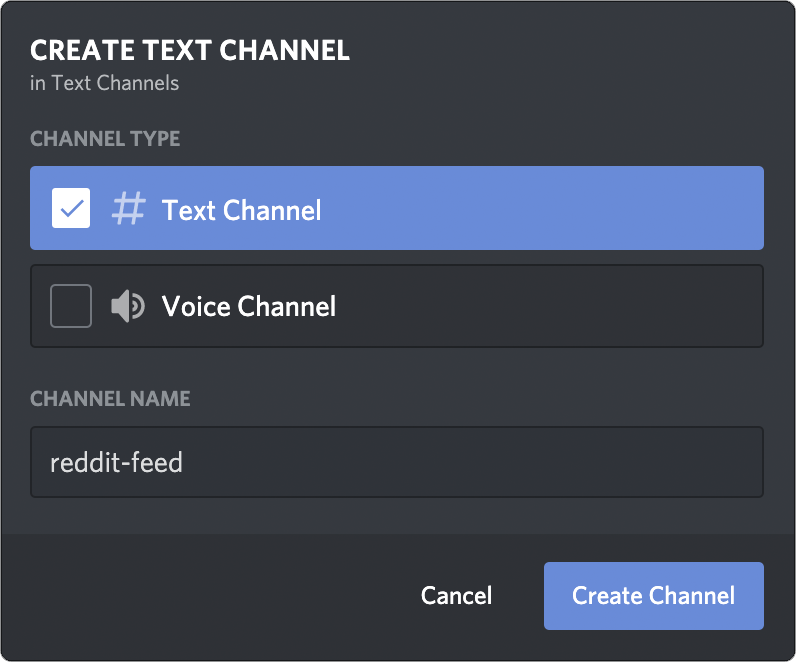
Once created, open the settings page for the new channel, and then select the Integrations section from the left menu:
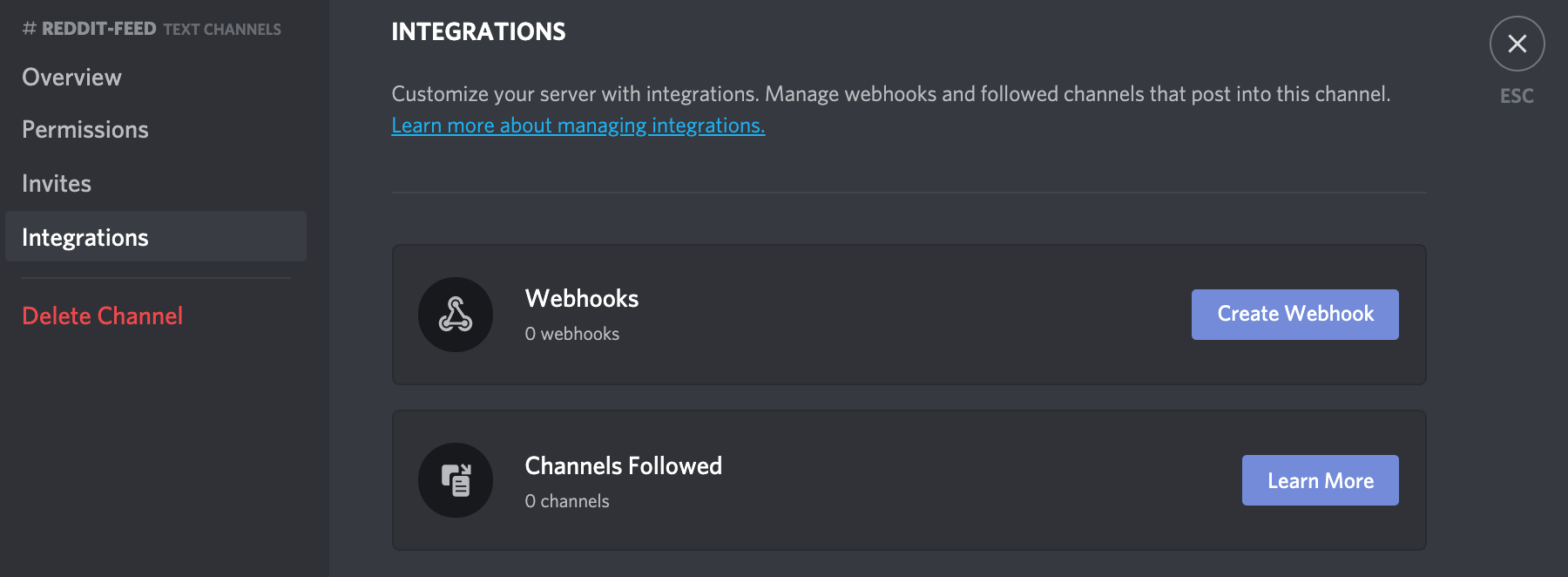
Finally, create a new webhook. You can call it whatever you’d like, I’ll simply name it Reddit Feed for this example. Be sure to save your changes, and voila! We can visit this page any time to copy our webhook URL.
Let’s test out our new webhook from the terminal, before we get started with code.
$ export WEBHOOK_URL="https://discord.com/api/webhooks/YOUR_WEBHOOK_HERE"
$ curl -X POST -H "Content-Type: application/json" -d '{"username": "Hello", "content": "World"}' $WEBHOOK_URL
Success!

Fetching posts
Now let’s start our actual Python code, we’ll begin by fetching a list of posts from Reddit. Luckily, Reddit makes this quite easy as you can append .json to most URLs to receive a JSON formatted response, for example: https://www.reddit.com/r/discordapp/new/.json which will return the 25 newest posts from /r/discordapp.
Let’s fetch it with Python
import requests
subreddit = 'discordapp'
req = requests.get(f'https://www.reddit.com/r/{subreddit}/new/.json', headers={
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"User-Agent": "discord-feed-bot"})
posts = req.json()['data']['children']
for post in posts:
print(f"Found post: {post['data']['title']}")
First of all we load the requests library for fetching data from Reddit.
Next we store the subreddit in a variable, and send a request to Reddit for the JSON of the latest posts. We use some headers here to make sure we avoid cache, and it’s also good practice to set a user-agent that identifies the creator - you could put an invite link to your Discord here, or similar.
We then loop through the individual posts, which are stored within the posts > data > children of the returned JSON.
Running the above should give an output similar to this:
Found post: Discord logged me out and is now telling me that my email doesn't exist
Found post: any ETA for Wayland support?
Found post: Is there a way to change a discord server's "permanent" invite link?
Found post: Discord's app breaking in an odd way. Send help.
[output truncated]
Only showing new posts
Now, the problem is, every time we run the above script we will grab all the new posts, regardless of whether or not we’ve seen them before. If we run this script as a one-minute cronjob, 25 posts will be repeatedly found each time.
There are many ways to deal with this, for example if we know we’ll be running this script every minute, we could check the post['data']['created'] timestamp and check whether or not the post was created in the last minute and then display it. This approach may miss posts if our cronjob fails for any reason, or the server running it reboots, so we could use a cache instead to help get round this.
By storing a list of post IDs we have already discovered, we can avoid sending duplicate messages, and it doesn’t matter if the script doesn’t run for a short while.
Caching locally
We’ll store a list of seen post IDs in a file. Let’s add a block of code at the top to check whether the file exists and load the data if so:
import json
try:
with open('db.json') as json_file:
db = json.load(json_file)
except FileNotFoundError:
db = []
Now we have a db list, which is either a list of post IDs we’ve already seen, or an empty list (because we haven’t seen any before). We’ll add any new IDs to this list later, and save it, with this block at the end of our script:
with open('db.json', 'w') as outfile:
json.dump(db, outfile, indent=2)
Checking whether posts are unique
We only need to store a single piece of uniquely identifying information for each post, and for that we can use the name field which will have a format like t3_abcde1. Let’s modify our loop to look like this:
for post in posts:
if post['data']['name'] not in db:
print(f"New post: {post['data']['title']}")
db.append(post['data']['name'])
We should now have some output that looks like this:
Dans-MacBook-Pro:Desktop dwalker$ python3 test.py
New post: Mic Distortion In Voice Calls and Mic Test
New post: Did anyone get that survey pop up?
...
[output truncated]
...
New post: Why is my phone number being listed as invalid when I have not used it for anything?
New post: Is there a way to get admin if you lost it?
Dans-MacBook-Pro:Desktop dwalker$ python3 test.py
Dans-MacBook-Pro:Desktop dwalker$ cat db.json
[
"t3_jiqtfg",
"t3_jiqoqr",
...
[output truncated]
...
"t3_jinmi4",
"t3_jinbaj"
]Dans-MacBook-Pro:Desktop dwalker$
Notice in the above example, on the second run of the script, no new posts were found, meaning our cache is working as expected.
Limiting the cache size
One thing to note, as it’s good practice to always think about scaling and future growth, is that our cache will grow infinitely with post IDs. In order to fix this, we can limit how much we store in our cache.
This is a simple fix, instead of dumping the entire db list to the output file, let’s just add the last 50 elements, by using db[-50:]. We can reference a list element from the end of a list, using negative numbers. By using a colon, we’re telling Python we want that element, and every element until the end of the list.
Why 50? Reddit will return 25 new posts, however, if some get deleted then we may display duplicates when older posts re-appear on the /new/.json page, so we’ll store an extra page worth as a buffer.
Our new output block looks like:
with open('db.json', 'w') as outfile:
json.dump(db[-50:], outfile, indent=2)
Posting to Discord
Now we’ve got a script that works nicely in the terminal, let’s get it posting to the Discord webhook we created earlier. To create a nice embed, we’re going to use the discord_webhook library, which can be installed with pip install discord_webhook (or pip3, depending on your setup). We’ll import the bits we need at the top of our file with:
from discord_webhook import DiscordWebhook, DiscordEmbed
webhook_url = "https://discord.com/api/webhooks/..."
Replace the above URL with your webhook URL you created earlier.
Building the embed
Our current loop simply prints out the name of the new post in the terminal. We could simply post the title to Discord, but Discord supports rich embeds - so why not make use of them?
Reddit posts come in three formats: text, image, and video. We know a post is a text post if the thumbnail property is set to self. Posts also contain a handy is_video property which identify video posts, and if a post matches neither of these then it’s an image post.
Unfortunately, Discord doesn’t currently support embedding videos that are playable within the chat client, so we’ll use the thumbnail and add some information to show that the post is a video.
webhook = DiscordWebhook(url=webhook_url)
permalink = f"https://www.reddit.com{post['data']['permalink']}"
if post['data']['thumbnail'] == 'self': # text post
embed = DiscordEmbed(title=post['data']['title'], url=permalink, description=post['data']['selftext'])
embed.set_footer(text=f"Posted by {post['data']['author']}")
elif post['data']['is_video']: # video post
embed = DiscordEmbed(title=post['data']['title'], url=permalink)
embed.set_image(url=post['data']['thumbnail'])
embed.set_footer(text=f"Video posted by {post['data']['author']}")
else: # image post
embed = DiscordEmbed(title=post['data']['title'], url=permalink)
embed.set_image(url=post['data']['url'])
embed.set_footer(text=f"Image posted by {post['data']['author']}")
Once the above code has executed, we have a webhook object, and an embed object. To add the newly created embed in to the webhook request and execute it, we simply do:
webhook.add_embed(embed)
webhook.execute()
Which is pretty self-explanatory. We could capture the output of webhook.execute() to check whether things went ok. One problem we typically encounter is being rate limited if we use the webhook in quick succession. A simple workaround for this is to import time at the top of the file, and then add a time.sleep(1) after the execution above, to pause for a second after each webhook post.
Fin
Run the script on a cronjob, and voila!
I keep a single small Digital Ocean VPS which hosts all my Discord bots and scrapers. An example cronjob to execute every 5 minutes might for this script could look like:
*/5 * * * * /usr/bin/python /root/scripts/reddit2discord.py >> /dev/null 2>&1
Some ideas to extend this script further could include filtering out certain posts, highlighting posts from certain authors, or using arguments with argparse to make the script more flexible.
You can also combine subreddits in the URL to pull from multiple subreddits, for example: https://www.reddit.com/r/discordapp+python/new/.json
The full code can be found (and starred if you found it helpful) as a Gist here.
Enjoy your new #reddit-feed ✌️